Data architecture
Sourcing and landing data for your product is one of the most important pieces of your solution design, and influences most other components in your deployment.
Sourcing data
The most common use of data by OEMs in Qlik Cloud is for in-memory analytics in Qlik Sense. This is used as the basis for embedded analytics, natural language insights, reporting, alerting, and many other capabilities. If you plan to use Qlik Cloud to deliver data directly from sources to targets via Qlik Cloud Data Integration, then review the introduction to Qlik Cloud Data Integration on Qlik Help.
Qlik Sense is primarily an in-memory analytics engine, with data refreshed into a Qlik Sense application on a schedule or an external trigger (for example, an update of a source database). This action is referred to as a reload. When a consumer user accesses the Qlik Sense application, they access this snapshot of data, rather than querying the data source directly - you can think of it as Qlik Cloud caches the data captured at the point of reload.
For fast-moving, or large datasets, it is possible to leverage direct-to-database hybrid models with approaches such as dynamic views, on-demand apps, SQL generation via direct query, or combinations like direct query with on-demand drill down.
As a rule, look to land the data into or as close to as possible to your customer tenants. Fewer hops and reduced distance means lower complexity and cost.
Identify your requirements
As you design your product, determine the necessary datasets for your solution. Any piece of data that you add should provide value to the consumer. Consider the following key aspects:
- Volume: how much data you need to provide valuable insights to your customers?
- Velocity: at what rate is data generated, and what update cadence do the analytics require to remain valuable?
- Variety: how many data sources and types do you need to load and transform for insight generation?
- Veracity: what in your data is important for the analyses you are aiming to provide to customers, and what is less valuable or relevant?
Additionally, your organization or customers may have requirements related to:
- Data privacy: Who can access the data? How is Personally Identifiable Information (PII) handled? Are GDPR and other privacy laws are adhered to?
- Data residency: what are the requirements for the physical location of the data in the world?
- Data access restrictions: Are database or storage buckets behind a firewall? Is IP-whitelisting acceptable? Is VPC placement required?
- Data encryption: who controls the encryption keys for data in Qlik Cloud, and how is data encrypted?
The answers to these questions will guide your data architecture choice, and, later, the app architecture you deploy to leverage it.
Analytics reload concurrency
In your contract, it will specify the number of concurrent reloads you can execute in Qlik Cloud. This limit is per entitlement, meaning that if you are entitled to 30 concurrent reloads in your contract, this total applies across all tenants you choose to deploy.
For more information and example calculations, see the analytics reloads overview.
High-level patterns
There are three main patterns, although it is possible to mix-and-match or use a hybrid of two approaches.
| Pattern | Great for |
|---|---|
| Distributed reloads - direct data access | All data volumes, scalable data sources, non-interactive authentication patterns, data not behind a firewall (or in S3 bucket in same AWS region) |
| Distributed reloads - distributed data access | Medium data volumes, all data sources, all authentication patterns, data behind firewall, data can be replicated into cloud storage by a tenant |
| Centralized reloads | Lower data volumes, more fragile data sources, data behind the firewall, interactive authentication only patterns, no access to cloud storage |
While these patterns are common, many other architectures are supported for various use cases.
Distributed reloads - direct data access
Each customer tenant connects directly to the data source. In most cases, this is over the public internet with the Qlik Cloud regional IPs whitelisted at the source, unless using Amazon S3 where internal network connectivity is supported.
In this approach:
- Each customer tenant connects directly to a cloud accessible data source to populate data in analytics apps.
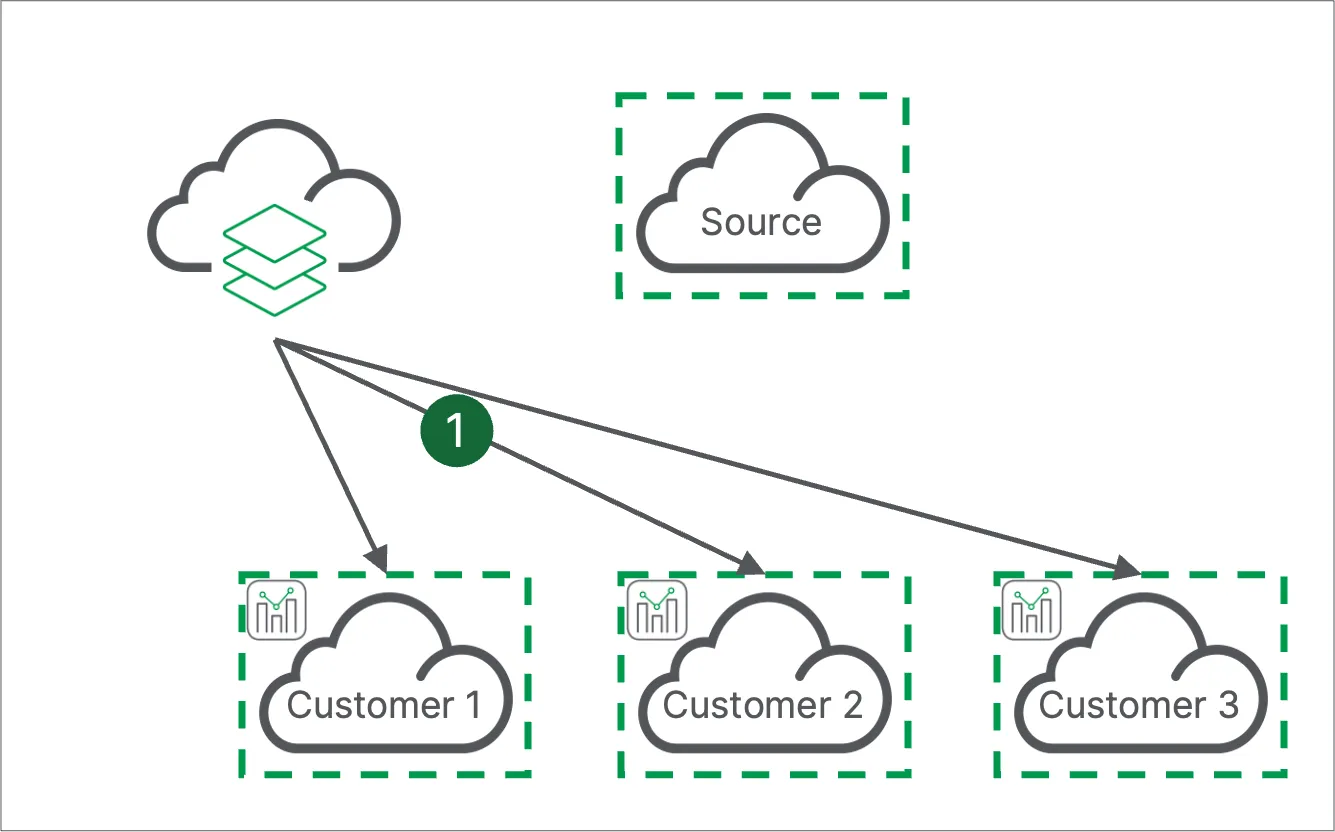
Why connect each tenant directly to the data source?
- Your data sources are accessible via the public internet with IP whitelisting.
- You wish to have full customer tenant isolation.
Upsides
- Data lands directly on customer tenants.
- Each tenant is a unique isolated instance, with no dependency on other Qlik Cloud components.
- You can opt to load data using data integration or analytics products in Qlik Cloud (data source dependent).
- All data source credentials stored on customer tenants.
- No cost for hosted infrastructure or virtual machines.
Considerations
- Data sources must be accessible via the public internet.
- Data sources connected to multiple tenants should be able to support intended request concurrency.
- Automation is required to deploy template applications and tenant configuration (using APIs, CLI, or Qlik Automate).
- Handling data connection credentials on customer tenants is required, which may increase maintenance burden.
Distributed reloads - distributed data access
This hybrid pattern involves reloading the Qlik Sense app component in the customer tenant while leveraging a single tenant that only the OEM partner can access for sourcing and landing data into a cloud data store for consumption by the other tenants in the estate. The source tenant can connect to data in private networks using a data gateway, or connect over the public internet as for the direct data access pattern.
In this approach:
- The source tenant connects to a firewalled data source via a data gateway.
- The source tenant stores the loaded data into cloud file storage, which will make it accessible to customer tenants.
- Customer tenants load data from the cloud file storage into analytics apps.
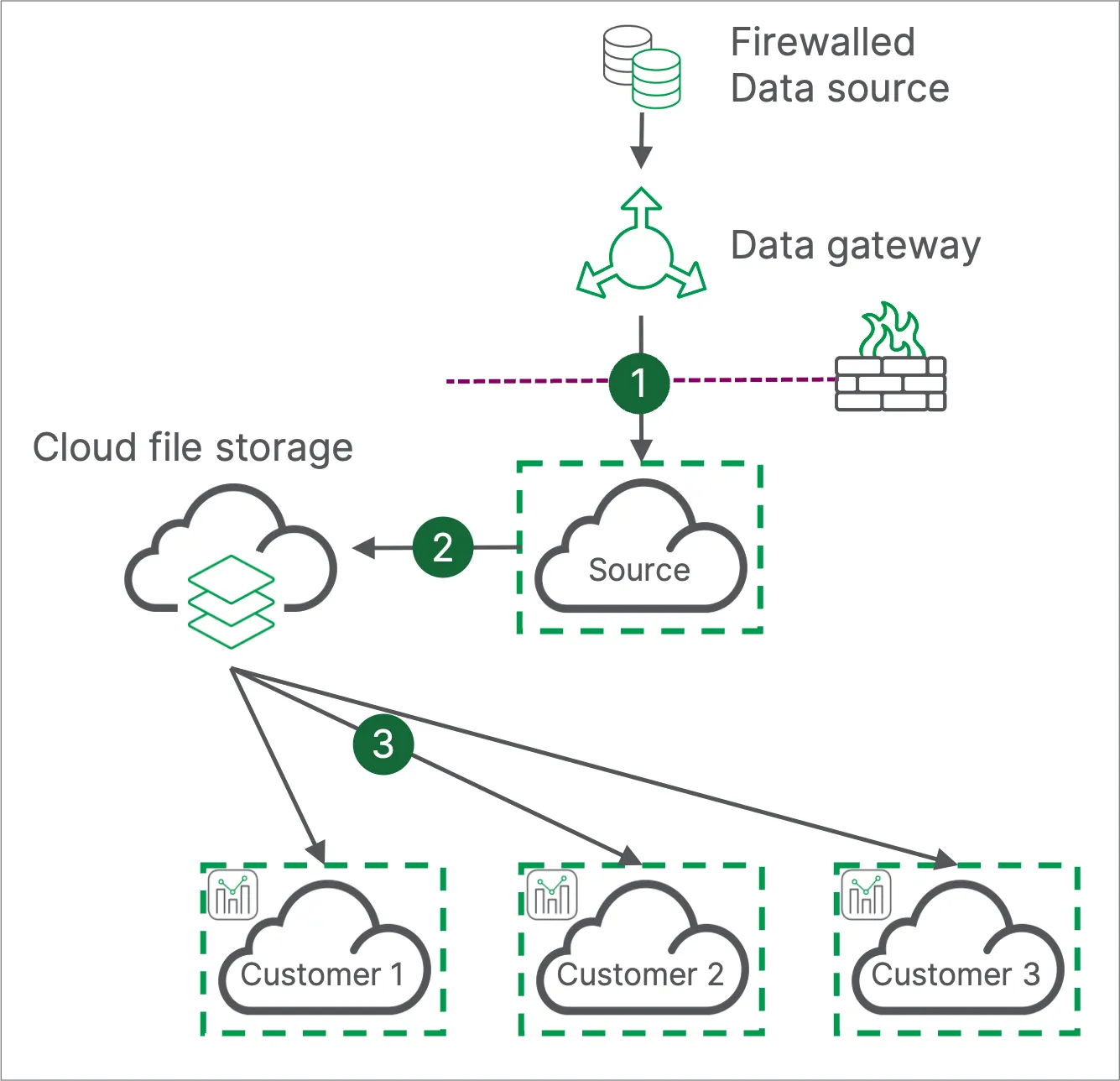
Why prepare data with a central tenant, but reload in customer tenants?
- Your data is not accessible to the public internet, or you cannot push data to customer tenants using your own tooling.
Upsides
- A single tenant connects to the data source, allowing more control when working with data sources that are sensitive or difficult to scale.
- Each tenant remains a unique isolated instance, dependent only on the OEM tenant for delivering data to a cloud file storage data source.
- You can opt to load data using data integration or analytics products in Qlik Cloud (data source dependent).
Considerations
- A virtual machine per gateway type is required. Additional gateways may be required to support higher throughput or high availability.
- This pattern is not recommended if working with end-customer managed data sources.
- The OEM tenant must prepare data for all customer tenants, creating a dependency.
- A data source accessible to the public internet is required for transferring data files between tenants.
- Handling data connection credentials on both OEM and customer tenants is required, involving automation.
Centralized reloads
This pattern is most suitable when no cloud data sources are available, but can also be used when distributing copies of the same application and data to customer tenants.
While this pattern offers full flexibility in how it connects to the data, it requires more external orchestration than other options due to the the size of the exported Qlik Sense apps, which can be substantial.
In this approach:
- The source tenant connects to a firewalled data source via a data gateway, or to a cloud accessible data source, and loads data into analytics apps.
- Third-party tooling is used to export each analytics app from the source tenant and move it to the relevant customer tenant for consumption.
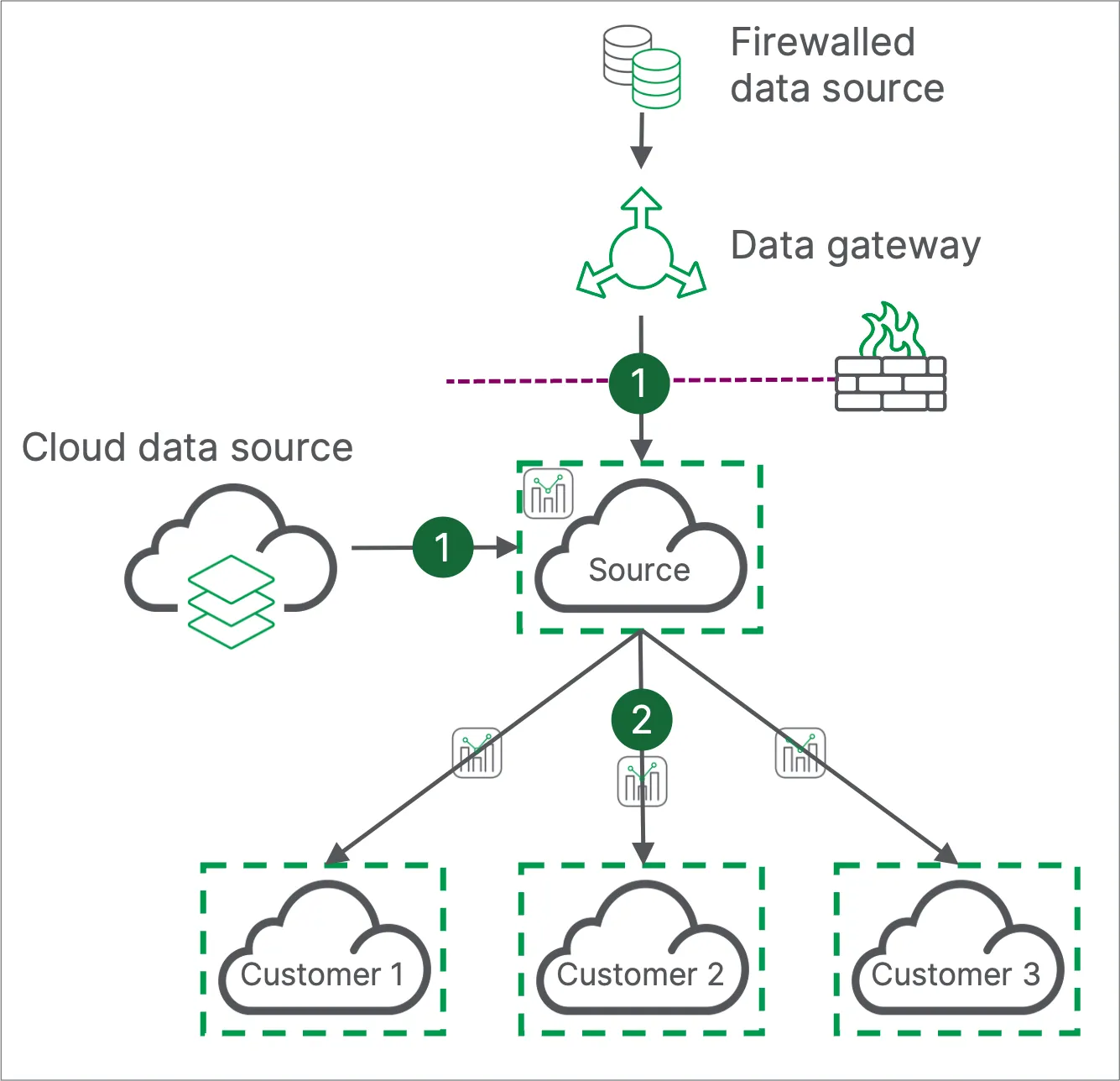
Why do all analytics reloads on one tenant?
- You have fewer end customers and want to keep a close eye on their reloads.
- You don’t wish to use automation to handle credentials, connections, and template distribution.
- Your data is not accessible to the public internet, or you cannot push data to customer tenants using your own tooling.
- You use a common dataset across all customers, such as benchmark data where you need load the data into the OEM tenant once, and each customer receives a slightly different slice.
Upsides
- All data connections and credentials are managed on a single tenant, which is easier if not using automation.
- Reload progress is easier to monitor as it happens on a single tenant.
- Each tenant is a unique isolated instance, with no dependency on other Qlik Cloud components.
- Reduced complexity on customer tenants, as no data files required since full Qlik Sense app is moved each time.
- Choice of CDC or on-load gateway solutions if required.
- All data source credentials stored on customer tenants.
- Incremental / CDC process may be simpler and cleaner.
Considerations
- A virtual machine per gateway type is required. Additional gateways may be required to support higher throughput or high availability.
- This pattern is not recommended if working with end-customer managed data sources.
- The OEM tenant must prepare data for all customer tenants, creating a dependency.
- This pattern requires moving a full copy of the data (albeit compressed) between the OEM and customer tenant each reload.
- Third-party tooling is required to move Qlik Sense app files between the OEM and customer tenants.
Other patterns
You can design a pattern to suit your use case if needed, such as deploying a gateway per customer tenant, or pushing files directly into each tenant using a tool such as Qlik Talend Studio.
Deploy a data gateway per tenant
Why deploy a gateway per tenant?
- You can’t use third-party tooling to distribute apps between tenants.
- Your data is not accessible to the public internet, you cannot route data through a central tenant, you cannot push data to customer tenants using your own tooling, or you require full customer data isolation end-to-end.
Upsides
- Data lands directly on customer tenants.
- Each tenant is a unique isolated instance, with no dependency on other Qlik Cloud components.
- Choice of CDC or on-load gateway solutions, and supports deployment of gateways to end customer infrastructure.
- All data source credentials are stored on customer tenants.
- Incremental and CDC process may be simpler and cleaner.
Considerations
- A virtual machine per tenant for each deployed data gateway is required. One gateway can connect to only one tenant.
- Automation is required to deploy template applications and tenant configuration (using APIs, CLI, or Qlik Automate).
- Handling data connection credential handling on customer tenants is required, which may increase maintenance burden.
- If your security team requires regular token rotation on gateway instances, manual effort will be required on each tenant for each rotation.
Push data into tenants
Why push data directly into a tenant?
- You have existing tooling that can prepare data files in formats supported by Qlik Cloud.
- Your data is not accessible to the public internet, you cannot route data through a central tenant, or you require full customer data isolation end-to-end.
Upsides
- Data lands directly on customer tenants.
- Each tenant is a unique isolated instance, with no dependency on other Qlik Cloud components.
- You have full control over the data pipeline, and can trigger analytics reloads via API once data lands.
- No data source credentials are stored in Qlik Cloud.
- Supports use cases where data changes infrequently, but changes need to be reflected in analytics apps immediately.
Considerations
- Third party infrastructure is required to operate this solution.
- If you do not wish to use regional OAuth clients for data provisioning, you will need to create credentials on each tenant and leverage these when distributing data files.
Next steps
Move onto the Privacy & security section, or go back to the playbook introduction.